Water Sports: Water QWOP (2023)
Water Sports: Water QWOP is a Unity-based reinforcement learning experiment. Conceptually, the system it sakes place wihtin is quite similar to the flash game QWOP. This project was developed as part of the Computational Explorations seminar at ITECH master's program in collaboration with Chris Kang, Markus Renner, and Cornerlius Carl. The team aimed to develop their own version of QWOP, with the primary objective of maximizing the distance water could be thrown.
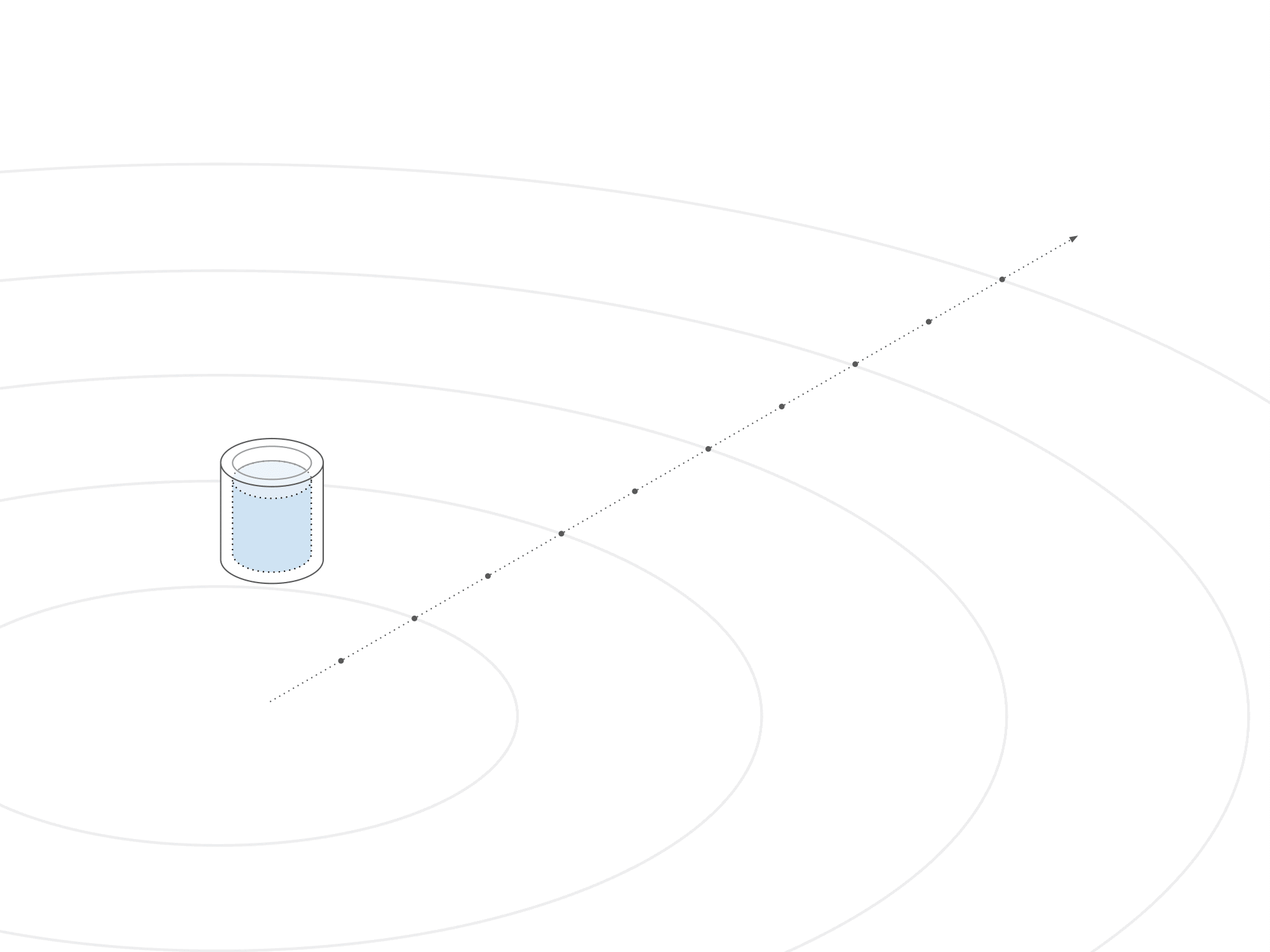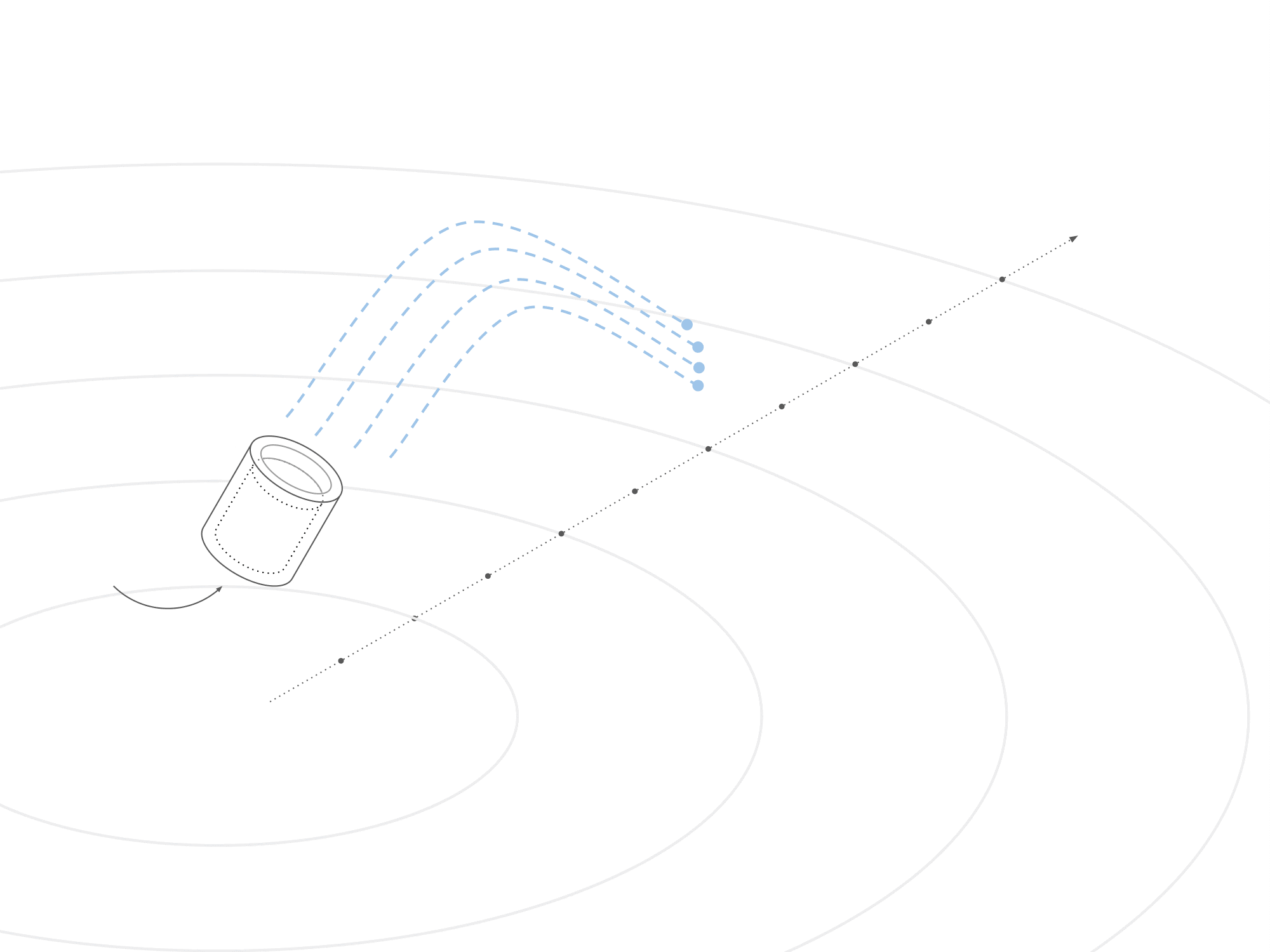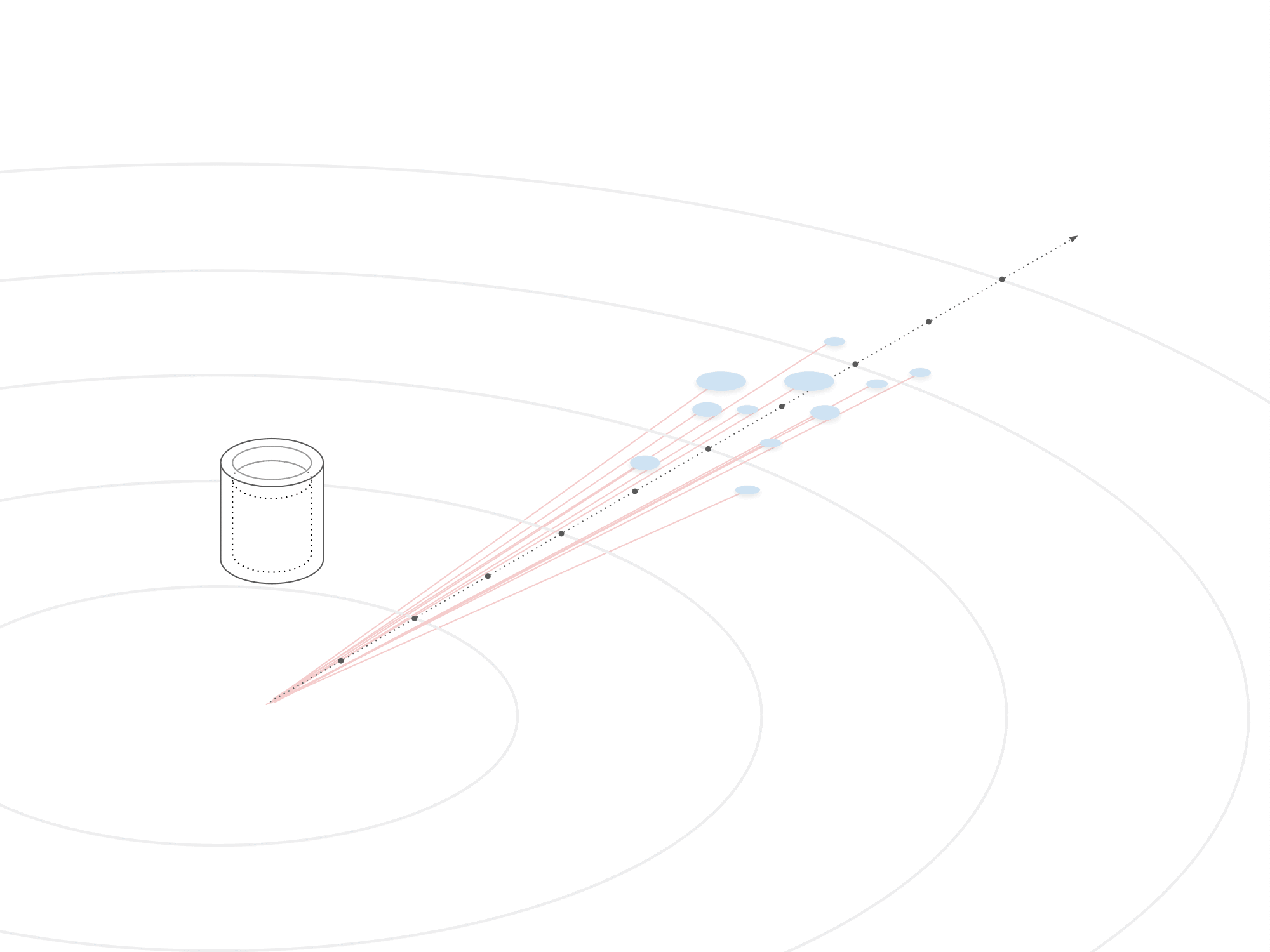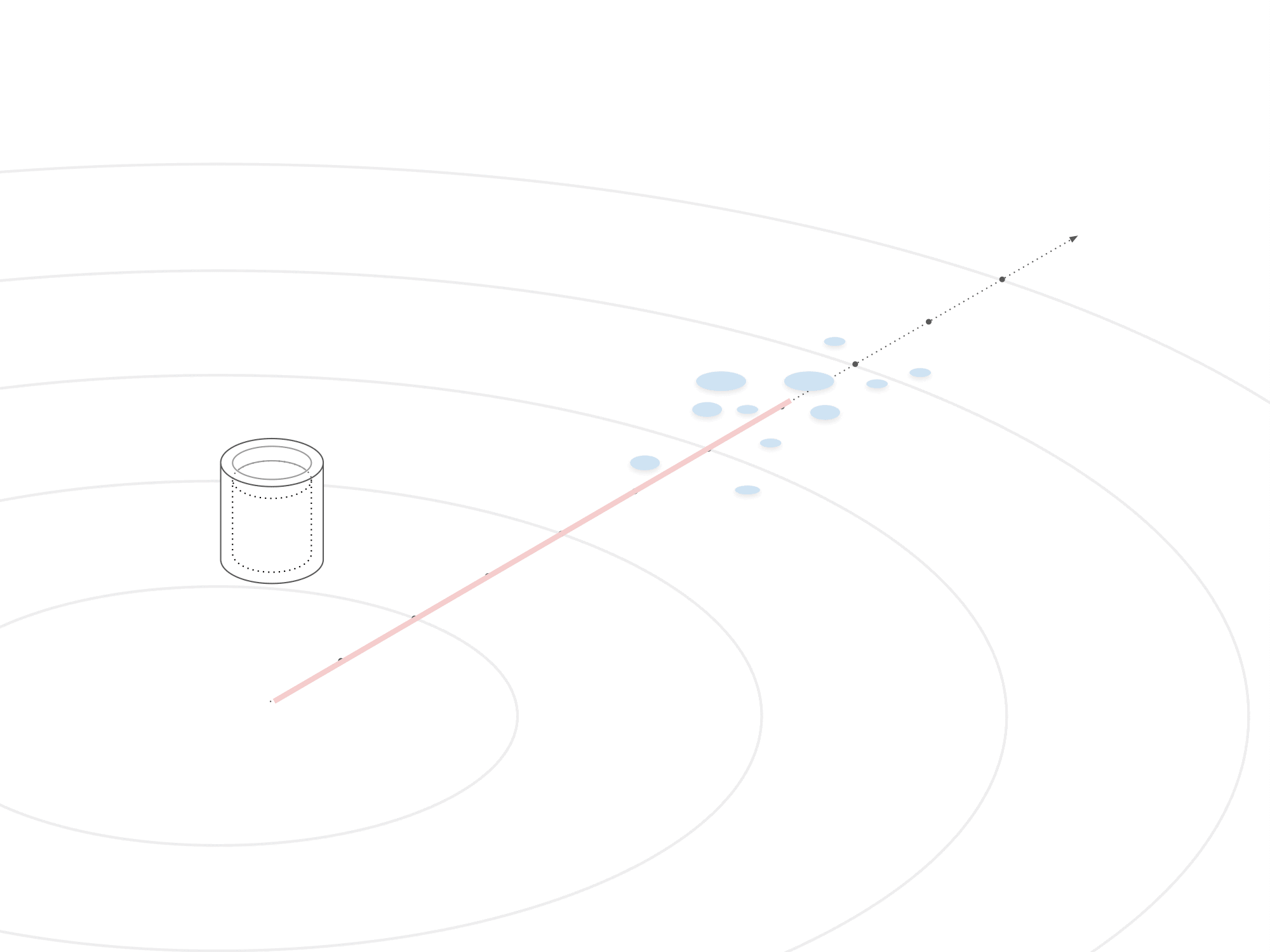
To establish a reward system, water droplets were programmed to propel themselves before freezing upon floor contact. Measurements were taken from the bucket's position to the landing spot, determining a reward based on average distance per throw. This reward calculation evaluated the agent's performance in maximizing throwing distance.
 |  |
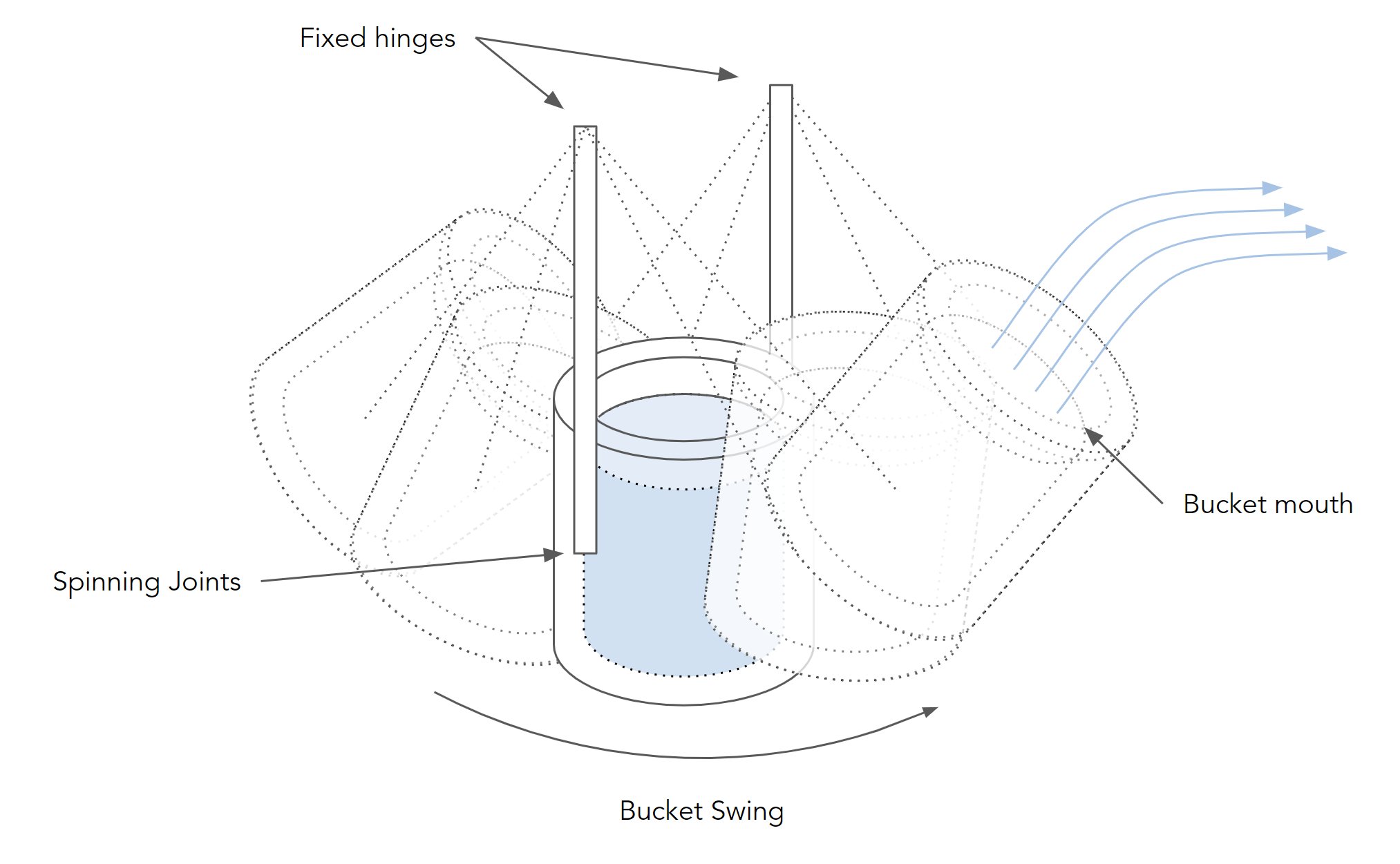
The Unity-based agent featured elongated arms with hinge joints, connected at the base, and equipped with a bucket. Water spheres within the bucket simulated throwing. The agent's arms are composed of four distinct sections, each equipped with five hinge joints. Among these joints, four are driven by motors that respond to specific key presses, enabling controlled articulation of the arms. The bucket, on the other hand, accommodates ten individual spheres that represent the water. These spheres possess the ability to move freely and are propelled in accordance with the velocity and movement of the bucket, simulating the throwing action.

The actuation of the right shoulder is assigned to the key Q, the right elbow to the key W, the left elbow to the key O, the right elbow to the key P, and the forward and backward rotation of the bucket at the wrists is controlled by the keys A and S, respectively.
With the environment now configured, a prefab was generated to streamline the setup process. This prefab served as a template for creating multiple agents that could undergo simultaneous training. By employing this approach, the training process could be efficiently conducted across numerous instances of the agent, allowing for parallel training and enhanced optimization. It was necessary to fine-tune both the observation inputs and reward system (based on average distance thrown) in order to correct this issue and achieve the desired behavior from the agent.

The agent underwent an extensive training process, encompassing approximately 18 million steps. Throughout this training period, the agent demonstrated a gradual improvement in its ability to throw water over a distance. It is worth noting that while the agent's performance falls short of that of a skilled human, with an average of 2.5 meter throws, the observed trend reveals promising signs of continual progress and learning over time. This incremental improvement suggests that with further iterations and refinement, the agent's performance has the potential to approach or even surpass human proficiency in the task.
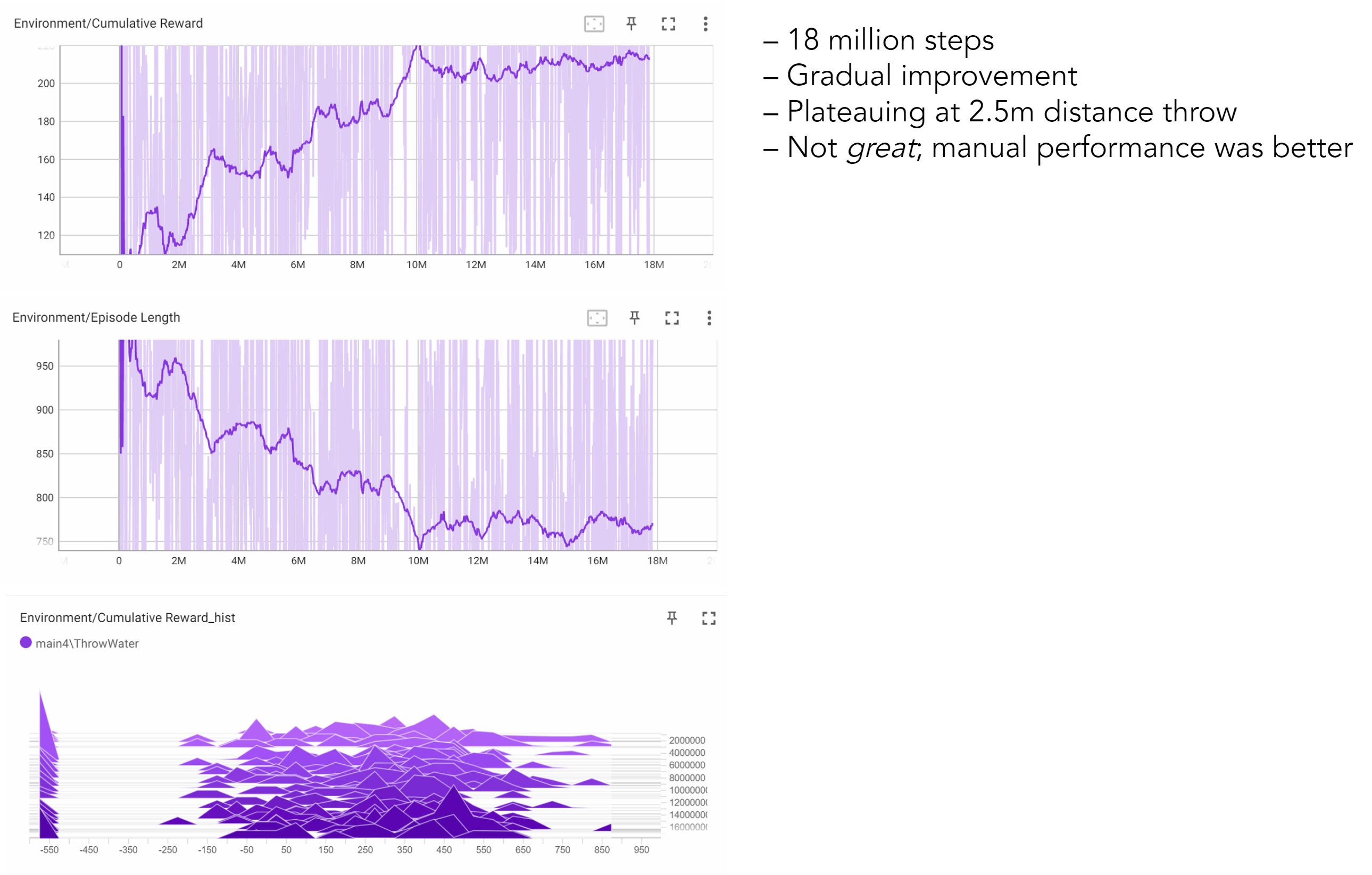
The observed behavior of the agent, as described above, indicates a tendency to swing the bucket back and forth before dumping the geometry out. It is hypothesized that additional training runs and further fine-tuning of parameters are necessary to achieve the desired outcome and refine the model's behavior. This iterative process of experimentation, adjustment, and evaluation is often required to optimize the training of machine learning models and align their actions more closely with the intended objectives. By conducting additional runs and carefully tweaking the parameters, it is expected that the agent's performance can be further improved and the undesired swinging behavior can be mitigated.
- 2025
- Primitive Slicer
- 2024
- Semantic Floor Plans
- ITECH Research Pavilion
- Wax Flamingos
- Phenomena Modeling
- 2023
- Honeycomb
- Water-QWOP
- Horse & Chariot
- Hyper-hydration
- 2022
- Sprawl & Resilience
- 2021
- Cybernetic Field
- Bubble-GAN
- 2020
- ELC: Carrick
- 15-112: placeHolder
- Collaborative Winding
- 2019
- Flood Museum
- Design Fabrication
- Spring Garden Hostel
- Modular Garden
- Bathhouse
- 2018
- Hoophouse
- Drawings